Machine Learning and MLOps engineering services
We design and deploy production-grade machine learning systems – fully integrated into your operations, continuously improving, and built for long-term control.
From data pipelines to model deployment and MLOps, every component is engineered as part of a single, structured system that operates reliably in real business environments.
Our Machine Learning capabilities
Machine learning systems engineered for production environments, continuous operation, and full integration into your business.

Data & pipeline engineering
We design and implement production-grade data pipelines, including ETL/ELT workflows, real-time streaming, and feature pipelines that ensure consistent, high-quality data flow into ML systems.

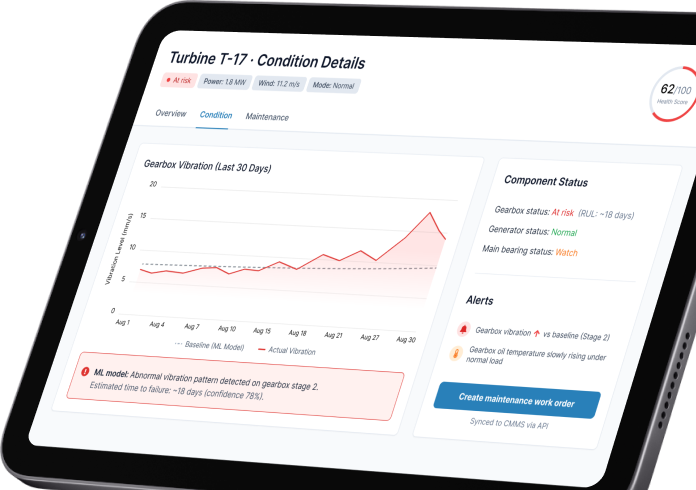
Multi-modal model engineering & edge AI
Our custom ML development services include developing ML models that combine multiple data sources – including sensor data, video, and structured inputs – and optimize them for real-time execution using quantization and hardware-aware optimization, including deployment on edge devices.

MLOps & continuous learning pipelines
We build automated MLOps pipelines with model monitoring, drift detection, version control, and controlled retraining cycles, ensuring stable performance and continuous system evolution.

System integration & operational embedding
As a part of our machine learning development services, we integrate ML systems into your infrastructure through APIs, event-driven architectures, and direct system connections, enabling real-time and batch decision execution within existing workflows.
Transform Your Business with ML
Go beyond off-the-shelf solutions. We build custom machine learning models that solve your unique challenges and drive real results.
ML development services across industries
Each system is engineered around your operational structure in your specific industry, ensuring stable integration, predictable behavior, and consistent performance at scale.
Finance & fintech
ML development services for transaction analysis, risk evaluation, and anomaly detection, fully integrated into financial operations. The result is systems that process large volumes of transactional and behavioral data in real time, producing consistent and traceable outputs.
Risk signals and scoring mechanisms are applied directly within decision flows, ensuring that actions follow defined logic and remain aligned with internal policies and regulatory requirements.

Healthcare & life sciences
We design ML systems that work with clinical, operational, and patient-generated data to support diagnostics, planning, and resource allocation. Structured and unstructured data – including medical records, imaging, and sensor data – is processed within controlled environments.
These systems provide timely, structured outputs that assist medical teams in decision-making while maintaining data governance and operational consistency across departments and facilities.

Logistics & supply chain
We build ML systems that coordinate demand, routing, and inventory across interconnected operations. Data from orders, transportation, warehouses, and external signals is processed continuously to support planning and execution.
The system dynamically adjusts routing, prioritization, and stock allocation based on real-time conditions, enabling faster responses to changes in demand or disruptions. Decisions are embedded into logistics workflows, improving timing, resource utilization, and overall operational efficiency.

Manufacturing & industrial
We deploy ML systems that continuously analyze equipment signals – vibration, temperature, acoustic, and process parameters – to detect deviations and support maintenance and production decisions in real time.
These systems operate at the machine and line level, combining edge processing with centralized analytics to ensure immediate response and full operational visibility. Maintenance actions, production adjustments, and quality checks are triggered directly within existing workflows, allowing teams to act with precision and consistency.

Engagement options
Clear, structured path from system evaluation to production deployment
We operate through a defined, engineering-led process that keeps scope, architecture, and delivery fully aligned from the start. Each stage is measurable, controlled, and designed to move your ML system into production without ambiguity.

ML architecture audit
Defined system scope and feasibility.
We evaluate your data, infrastructure, and integration landscape to define a precise ML system architecture.
You receive:
- Structured assessment of data pipelines and system readiness
- Defined ML use cases aligned with operations
- Architecture blueprint with clear system boundaries
- Implementation roadmap with scope and priorities
Refer to this engagement model when you need to establish a clear ML foundation before execution.

System architecture design
Detailed ML system blueprint.
We design the full ML system architecture before development begins.
This includes:
- Data flow design and pipeline structure
- Model placement and interaction logic
- MLOps pipeline configuration and lifecycle design
- Integration points with your existing systems
The result is a complete, build-ready system design with defined components and responsibilities.

Production system delivery
Deployment of integrated, operational ML systems.
We build and deploy the ML system as a fully integrated part of your environment.
This includes:
- Implementation of data pipelines, models, and APIs
- Deployment through controlled CI/CD and MLOps workflows
- Integration with operational systems and processes
- System validation, monitoring, and performance tracking
The system is delivered as a working, production-ready solution designed for continuous operation and improvement.
Business impact of Machine Learning
Done right, Machine Learning doesn’t just run in notebooks. It works in your systems, supports your team, and improves your bottom line. That’s what we focus on: practical, measurable impact.
Here’s what machine learning should deliver:
- Save 1,000+ hours by automating repetitive tasks across operations, support, and analytics.
- Handle over 60% of Tier-1 support requests with ML-powered virtual assistants.
- Cut churn by 20% using models that predict when and why customers are about to leave.
- Boost conversions by up to 20% with personalized offers, recommendations, and content.
- Reduce fraud losses by 30–40% through real-time anomaly detection and behavioral risk scoring.
- Increase forecasting accuracy for sales, demand, and risk, helping teams act early, not late.
- Deploy models 3× faster with structured MLOps workflows.

From Idea to Intelligent Application
Have a great idea for an AI / ML product? Our experts will guide you through the entire process, from concept to deployment.
Continuous learning by design (ADLC)
We design AI systems as continuously operating systems, where each stage is defined, connected, and managed as part of a single lifecycle.

Data pipelines prepared for real use
We start by structuring your data into stable pipelines that collect, clean, and transform it for both training and real-time operation. The same pipelines are used across the system, ensuring consistency between how models are trained and how they perform in production.

Model development aligned with business metrics
Models are developed and trained using your operational data and evaluated against clearly defined performance metrics. This ensures the model reflects real use cases and delivers measurable results from the start.

Validation and controlled deployment
Before going live, each model is validated against real scenarios and packaged as part of your system. Deployment is handled through structured pipelines, ensuring a smooth and predictable transition into production.

Integration into operational workflows
The model is integrated directly into your systems – APIs, platforms, and workflows – where it begins generating predictions that support decisions or trigger actions.

Continuous performance monitoring
Once in production, we continuously track how the model performs using live data. This provides clear visibility into accuracy, behavior, and system impact over time.

Structured retraining and version updates
As new data is collected, models are retrained through controlled pipelines. Each update is tested, versioned, and deployed without disrupting ongoing operations.
Enterprise ML maturity model
Machine learning evolves from isolated models to systems that execute decisions – we move your ML to the next level.
 Level 1. Structured analytics
Level 1. Structured analytics
 Level 2. Predictive MLOps systems
Level 2. Predictive MLOps systems
 Level 3. Agentic & edge AI systems
Level 3. Agentic & edge AI systems
Structured analytics
ML exists separately from your systems.
Models generate predictions, but they are not embedded into workflows or operations.
Example:
A demand forecasting model runs weekly in a notebook and exports results into Excel for manual planning.
What we do:
- Structure your data and pipelines
- Align models with real use cases
- Prepare ML for system integration
Predictive MLOps systems
ML is embedded into your systems.
Predictions are delivered directly into workflows and used inside your platforms.
Example:
A fraud detection model scores transactions in real time and flags suspicious activity inside your payment system.
What we do:
- Build MLOps pipelines for training and deployment
- Connect models to your systems via APIs and events
- Ensure stable, continuous operation
Agentic & edge AI systems
ML executes decisions inside your operations
Systems process data in real time and trigger actions within workflows.
Example:
A logistics system detects a delay, automatically reroutes shipments, updates the ERP, and notifies stakeholders.
What we do:
- Deploy edge-optimized and real-time models
- Build multi-modal ML systems
- Enable automated decision execution
Production machine learning systems
We design and build complete machine learning systems that operate directly inside your business processes. Machine learning is implemented as a fully integrated part of your operations – where data flows reliably, predictions are generated consistently, and outputs are used immediately within your workflows. The result is a machine learning system that runs as part of your infrastructure – predictable, measurable, and aligned with how your business operates.

Create Custom ML for Your Business
Off-the-shelf AI isn’t enough. We design and build machine learning solutions specifically for your needs, goals, and data.
Our tech expertise that powers ML solutions
We work at the intersection of data, software, and machine learning, building solutions that operate reliably in real-world conditions. When providing AI and Machine Learning development services, our team combines research-level understanding with practical development skills, allowing us to design systems that are not only smart, but stable, explainable, and scalable.
Here’s a breakdown of our core engineering capabilities.
Machine learning algorithms
In our custom machine learning development services, we implement a wide range of ML models, selected based on task type, data constraints, interpretability requirements, and infrastructure. This includes:
- supervised learning models (logistic regression, decision trees, XGBoost, SVMs) for classification, scoring, and forecasting;
- unsupervised models (clustering, anomaly detection) for pattern discovery and segmentation;
- time series models for demand, sales, and risk forecasting (ARIMA, Prophet, ML ensembles);
- hybrid pipelines combining rules, heuristics, and ML models to handle edge cases and fallback logic.
All models are selected based on empirical benchmarks – not buzz – and validated on your business-specific KPIs.
Deep learning
When task complexity or unstructured data demands more, we build and train deep neural networks using:
- CNNs for visual input (quality inspection, OCR, medical imaging, object tracking);
- RNNs, LSTMs, and Transformers for time series and NLP (document analysis, event prediction, chat models);
- autoencoders for noise reduction, dimensionality reduction, and anomaly detection;
- custom architectures for multimodal inputs or hybrid systems (e.g., text + tabular + visual).
We support distributed training, hardware acceleration (GPU/TPU), and model versioning, ensuring DL models are production-ready – not stuck in experimentation.
AutoML
We use AutoML tools to reduce time-to-first-model in rapid prototyping and internal systems. Tools include:
- Google Cloud AutoML / Vertex AI;
- AWS SageMaker Autopilot;
- H2O.ai;
- MLJAR and internal AutoML wrappers for light tasks.
Unlike black-box automation, we audit every model generated, tune key parameters manually when needed, and benchmark against custom-built alternatives. AutoML is a tool – not a shortcut.
Big data processing
High-volume data needs systems that can scale and recover. We design and implement:
- distributed data pipelines using Apache Spark, Hadoop, and Airflow;
- real-time data streaming via Apache Kafka and Flink;
- cloud-native event processing on AWS (Kinesis), GCP (Pub/Sub), and Azure Event Hub;
- ETL and ELT pipelines capable of processing terabytes/day – for training and real-time inference.
We optimize data flow to reduce lag, memory footprint, and runtime – so your models learn from the freshest, richest signals available.
| Services | Tools samples |
|---|---|
ML & AI frameworks/libraries |
TensorFlow, PyTorch, Scikit-learn, Keras, XGBoost, LightGBM, OpenCV, Hugging Face Transformers, spaCy, NLTK, FastText, LangChain, MLlib (Apache Spark). |
Programming languages |
Python, R, Java, C++, JavaScript / TypeScript (for frontend/backend integration), Go, Scala. |
Data & pipeline tools |
Apache Airflow, Apache Kafka, Apache Spark, Pandas, NumPy, Dask, dbt (for data transformation). |
Cloud platforms & infrastructure |
AWS (SageMaker, EC2, S3, Lambda), Microsoft Azure (Machine Learning, Blob Storage), Google Cloud Platform (Vertex AI, BigQuery, AutoML), IBM Cloud, DigitalOcean (for small-scale deployments), Snowflake. |
DevOps & MLOps |
Docker, Kubernetes, MLflow, DVC, Kubeflow, Jenkins, GitHub Actions, Terraform, Prometheus + Grafana (for monitoring). |
Databases & storages |
PostgreSQL, MySQL, MongoDB, Cassandra, Redis, ElasticSearch, Amazon Redshift, BigQuery, MinIO (S3-compatible object storage). |
Visualization & dashboarding |
Power BI, Tableau, Looker, Grafana, Streamlit, Dash by Plotly, Superset. |
ML & AI frameworks/libraries
Programming languages
Data & pipeline tools
Cloud platforms & infrastructure
DevOps & MLOps
Databases & storages
Visualization & dashboarding
TensorFlow, PyTorch, Scikit-learn, Keras, XGBoost, LightGBM, OpenCV, Hugging Face Transformers, spaCy, NLTK, FastText, LangChain, MLlib (Apache Spark).
Python, R, Java, C++, JavaScript / TypeScript (for frontend/backend integration), Go, Scala.
Apache Airflow, Apache Kafka, Apache Spark, Pandas, NumPy, Dask, dbt (for data transformation).
AWS (SageMaker, EC2, S3, Lambda), Microsoft Azure (Machine Learning, Blob Storage), Google Cloud Platform (Vertex AI, BigQuery, AutoML), IBM Cloud, DigitalOcean (for small-scale deployments), Snowflake.
Docker, Kubernetes, MLflow, DVC, Kubeflow, Jenkins, GitHub Actions, Terraform, Prometheus + Grafana (for monitoring).
PostgreSQL, MySQL, MongoDB, Cassandra, Redis, ElasticSearch, Amazon Redshift, BigQuery, MinIO (S3-compatible object storage).
Power BI, Tableau, Looker, Grafana, Streamlit, Dash by Plotly, Superset.
Solve Complex Challenges with ML
Tackle your toughest challenges with the power of custom machine learning. We develop robust, scalable solutions for even the most complex business problems.
Projects we recently released





The system has produced a significant competitive advantage in the industry thanks to SumatoSoft’s well-thought opinions.
They shouldered the burden of constantly updating a project management tool with a high level of detail and were committed to producing the best possible solution.

I was impressed by SumatoSoft’s prices, especially for the project I wanted to do and in comparison to the quotes I received from a lot of other companies.
Also, their communication skills were great; it never felt like a long-distance project. It felt like SumatoSoft was working next door because their project manager was always keeping me updated. Initially.

We tried another company that one of our partners had used but they didn’t work out. I feel that SumatoSoft does a better investigation of what we’re asking for. They tell us how they plan to do a task and ask if that works for us. We chose them because their method worked with us.

SumatoSoft is the firm to work with if you want to keep up to high standards. The professional workflows they stick to result in exceptional quality.
Important, they help you think with the business logic of your application and they don’t blindly follow what you are saying. Which is super important. Overall, great skills, good communication, and happy with the results so far.

They are very sharp and have a high-quality team. I expect quality from people, and they have the kind of team I can work with. They were upfront about everything that needed to be done.
I appreciated that the cost of the project turned out to be smaller than what we expected because they made some very good suggestions. They are very pleasant to work with.

Rivalfox had the pleasure to work with SumatoSoft in building out core portions of our product, and the results really couldn’t have been better.
SumatoSoft provided us with engineering expertise, enthusiasm and great people that were focused on creating quality features quickly.

SumatoSoft succeeded in building a more manageable solution that is much easier to maintain.

Thanks to SumatoSoft’s can-do attitude, amazing work ethic, and willingness to tackle clients’ problems as their own, they’ve become an integral part of our team. We’ve been truly impressed with their professionalism and performance and continue to work with the team on developing new applications.
We are completely satisfied with the results of our cooperation and will be happy to recommend SumatoSoft as a reliable and competent partner for development of web-based solutions
Why SumatoSoft

Jupyter Notebook to Production
Data Scientists build models. Software Engineers build applications. We build both. The reason your ML pilot failed is that your data scientists didn’t know how to integrate their Python scripts with your legacy SQL databases or handle live API rate limits. Our Dual-Engine team bridges the gap between the lab and the factory floor, engineering the CI/CD pipelines to securely operationalize your AI.

The MLOps & Continuous Learning Pipeline
Models degrade the second they go live. We engineer Automated MLOps Pipelines. We implement telemetry tracking (using tools like MLflow or Weights & Biases) to monitor your model for ‘Data Drift.’ When accuracy drops below the threshold, our pipeline automatically triggers a retraining cycle using the latest production data, ensuring your AI gets smarter, not dumber, over time.

AI Governance & Shadow ML
Stop ‘Shadow ML’ from creating massive liability. We engineer Model Governance and Explainability into your core architecture. We utilize frameworks like SHAP and LIME so that every decision your ML model makes can be mathematically audited and explained to regulators, ensuring strict compliance in finance, healthcare, and logistics.

No Vendor Lock-In
Total infrastructure freedom. We build your ML pipelines using containerized, open-source standards (Kubeflow, Docker, MLflow). If you want to run inference on AWS SageMaker, Azure, or completely on-premise on your own bare-metal servers, you own the IP and control the infrastructure.
Awards & Recognitions





Let’s start
If you have any questions, email us info@sumatosoft.com


Frequently asked questions
How do you prevent your machine learning model’s accuracy from degrading over time (model drift)?
All models experience data drift as real-world conditions change. We engineer automated MLOps pipelines using platforms like MLflow or Kubeflow. We set mathematical thresholds for precision and recall. When accuracy drops below the defined threshold, the pipeline captures new anomalous data, triggers a retraining sequence, and deploys updated weights through a shadow deployment before switching live traffic.
How do you deploy heavy machine learning models like computer vision in offline environments or factories with poor internet?
We utilize model quantization and edge AI. We compress neural networks using frameworks like TensorFlow Lite or TensorRT to run directly on local edge gateways or microcontrollers. The model processes video or sensor data locally in milliseconds and transmits only a compact result payload to the cloud.
Our data is messy, siloed, and unlabeled. Can you still build an ML model?
Before any model development, we perform a data readiness audit. Our data engineers build ETL pipelines to centralize, clean, and vectorize siloed data. For unlabeled datasets, we deploy unsupervised learning models such as autoencoders to establish baselines without requiring large volumes of manually tagged data.
What is the difference between deploying software (SDLC) and deploying machine learning (ADLC)?
Standard software is deterministic, where the same input produces the same output. Machine learning operates on changing inputs and produces probabilistic outputs. We engineer ADLC architecture that versions code, data, and model weights together, ensuring full traceability and control for compliance.
How do you prove to regulators that your machine learning model produces explainable decisions?
We engineer explainable AI architectures using frameworks like SHAP or LIME. Models output mathematical weight distributions alongside predictions, allowing compliance teams to trace which data points influenced each decision and maintain full auditability.






