
TL;DR
- ADLC (Agentic Development Lifecycle) is a software engineering framework for developing probabilistic AI systems with governance, cost predictability, and security controls built in. It builds on the traditional Software Development Lifecycle (SDLC) by adding governance for systems whose outputs are non-deterministic.
- Why it exists: Gartner predicts that more than 40% of agentic AI projects will be canceled by the end of 2027, primarily due to escalating costs, unclear business value, and inadequate risk controls. SDLC was never designed to govern systems that hallucinate, drift, or burn variable token budgets.
- What you get: Five engineering pillars (zero-hallucination architecture, financial governance, security by architecture, human-in-the-loop control, multi-modal grounding) executed across seven phases – from AI readiness assessment to continuous evaluation.
- When to use it: Any time your system involves probabilistic generation, fine-tuning, or agent orchestration. For pretrained models used as-is, a lightweight ADLC track is sufficient.
What is the Agentic Development Lifecycle (ADLC)?
The Agentic Development Lifecycle (ADLC) is a software engineering framework for developing probabilistic AI systems with governance, cost predictability, and security controls built in. It defines the phases, deliverables, and control gates required to take an AI initiative from a business hypothesis to a continuously evaluated production system – without the failure modes that traditional engineering processes are blind to.
The term emerged in response to a structural problem: enterprise software teams have spent four decades perfecting deterministic engineering practices, and those practices break down the moment a system’s output is sampled from a probability distribution. ADLC formalizes the additional disciplines – token economics, red-teaming, evaluation harnesses, drift monitoring – that probabilistic systems require, and integrates them with the SDLC artifacts engineering organizations already trust.
ADLC sits in the same conceptual neighborhood as ISO/IEC 42001:2023, the world’s first certifiable AI management system standard, published in December 2023. ISO/IEC 42001 specifies what an AI management system must do; ADLC specifies how engineering teams build and operate the systems that live inside it.
Why traditional SDLC fails with AI systems
SDLC remains the foundation for building reliable software. The challenge with AI systems is that SDLC was built around five assumptions that don’t hold for them. Five concrete points of failure follow.
Deterministic testing cannot validate probabilistic outputs
In a traditional SDLC, QA runs a test case three times and expects identical results. In an AI system, the same prompt may produce three different answers – and all three can be technically “correct.” This breaks unit-testing as a discipline. Probabilistic systems require evaluation harnesses (RAGAS, OpenAI Evals, custom rubrics) that score outputs against intent, not equality. A regression isn’t a binary pass/fail; it’s a distributional shift in answer quality. Teams that try to bolt assertion-based tests onto an LLM ship false confidence.
Static infrastructure cost models miss token burn
Traditional infrastructure budgeting treats compute as a fixed line item: provision N servers, pay M dollars per month. AI systems consume tokens – a unit billed per inference, scaling with prompt length, user behavior, and model choice. A feature that costs $400 a month in development can cost $40,000 a month under load if no one modeled token burn. SDLC’s capacity-planning rituals don’t capture this. WRITER’s 2026 enterprise AI survey found that while 59% of companies invest more than $1 million annually in AI, only 29% see significant return on generative AI investments – a gap that almost always traces back to cost models that ignored variable inference economics.
Versioned releases break under the continuous model drift
SDLC assumes that v2.4.1 of an application behaves the same way today as it did at release. AI systems built on third-party model APIs (OpenAI, Anthropic, Google) inherit silent updates: the underlying model changes, evaluation scores drift, and a feature that worked yesterday subtly degrades today. Your code didn’t change, but your behavior did. SDLC has no concept of “the dependency we don’t control silently rewrote itself.”
Security perimeters don’t cover prompt injection
Traditional threat modeling assumes input is data and code is code. Prompt injection collapses that boundary – a malicious instruction embedded in a customer email, a PDF, or a webpage retrieved by your agent can rewrite the system’s behavior at inference time. RBAC (role-based access control), VPC (virtual private cloud) isolation, and OWASP-style web app threat models are necessary but not sufficient. ADLC adds an explicit threat surface: the prompt itself.
QA processes assume reproducible bugs
A bug report in traditional software is “click X, observe Y, expected Z.” An AI failure is often “the model said something subtly wrong, three times out of forty, and we can’t reproduce it on demand.” SDLC’s bug-triage rituals (file a ticket, write a test that fails, fix, watch the test pass) collapse when failures are statistical. ADLC replaces “reproducible bug” with “evaluation slice that drops below threshold” – a fundamentally different unit of work.
The five pillars of ADLC

The Five Pillars are the engineering principles that hold up every production AI system SumatoSoft has shipped. Each pillar is a non-negotiable design property, not a tool choice.
Zero-hallucination architecture
Zero-hallucination architecture is a system design pattern that constrains LLM output to grounded, retrievable facts. Rather than promising perfection, it sets an engineering constraint: any factual claim must trace to a source the system retrieved at inference time. Implementations combine retrieval-augmented generation (RAG), structured tool-calling, citation enforcement, and refusal behaviors when no grounded answer exists. Recent multi-agent RAG research has demonstrated reductions in hallucination rates from 15% to 1.45% on production query loads – an order-of-magnitude improvement that only becomes possible when the architecture itself, not a post-hoc filter, enforces grounding.
Financial governance (token burn modeling)
Financial governance is the discipline of forecasting, capping, and reporting on inference cost as a first-class engineering concern. It includes per-feature token budgets, request-level cost telemetry, automatic model downshifting (e.g., routing easy queries to a cheaper model), and CFO-readable dashboards. Without financial governance, AI features ship as open-ended liabilities. Token economics belong on the same page as latency and uptime – and a separate phase (Phase 2) of ADLC is dedicated to it.
Security by architecture (VPC-isolated, RBAC, zero retention)
Security by architecture is a deployment posture in which AI components run inside the customer’s network boundary, with role-based access control on every input and output, and zero data retention by the model provider. Personally identifiable information (PII) never leaves the VPC; logs redact prompts; vector databases enforce row-level security. Architectural security tends to pass CISO reviews on the first try, while bolt-on security rarely does.
Human-in-the-loop control
Human-in-the-loop (HITL) is a control pattern in which the system explicitly hands off decisions to a human operator above a configurable risk threshold. Treat HITL as a designed-in feature with its own UI, queue, latency budget, and escalation policy. A better question than “should the AI do this autonomously?” is “where do we draw the line, and what does the handoff look like?” ADLC requires that line to be documented before the system ships.
Multi-modal grounding
Multi-modal grounding is a retrieval pattern that pulls structured data (databases, APIs), unstructured text (documents, transcripts), and – increasingly – images, audio, and sensor streams into a single context window. It matters because production decisions rarely live in one modality: a clinical trial matcher needs the patient record, the inclusion criteria PDF, and the trial registry API. Single-source RAG works as a starting point, while production systems usually require multi-modal grounding.
SDLC vs ADLC: side-by-side comparison
| Engineering Dimension | Traditional SDLC | Agentic ADLC |
|---|---|---|
| System logic model | Deterministic, rule-based | Probabilistic, sampled from a distribution |
| Quality assurance method | Unit tests, integration tests, reproducible bug reports | Evaluation harnesses (RAGAS, custom rubrics), distributional regression, red-teaming |
| Cost governance model | Fixed infrastructure capacity planning | Token burn modeling, per-feature inference budgets, model routing |
| Release & stability model | Versioned, immutable releases | Continuous evaluation, drift monitoring, model-version pinning where required |
| Input-output behavior | Predictable, reproducible | Variable across runs; output evaluated by intent, not equality |
| Security threat model | OWASP web app, RBAC, network perimeter | Above plus prompt injection, data exfiltration via context, model jailbreaks |
| Observability | Logs, metrics, distributed traces | Above plus per-prompt traces, eval scores, hallucination flags, citation audits |
| Team composition | Engineers, QA, SRE, security | Above plus AI evaluation engineers, prompt engineers, red-teamers, AI governance leads |
| Failure mode | Crashes, exceptions, wrong calculations | Confidently wrong answers, silent drift, runaway token spend, prompt injection |
ADLC works alongside SDLC, adding a parallel track for AI components within the same engineering organization. Code that calls a model goes through ADLC. Code that does not goes through SDLC. Both meet at the same release pipeline, with the AI-side gates added on top.
The 7 phases of the Agentic Development Lifecycle

Each phase has a defined goal, key activities, common tools, deliverable, and the failure mode to avoid. Phase 7 feeds back into phases 2 and 3, so ADLC works as a continuous cycle that keeps running after deployment.
Phase 1 – AI readiness and value assessment
Goal: Determine whether the proposed initiative is fit for AI, and whether the organization is fit to deliver it.
Key activities:
- Map the business outcome to a measurable improvement (cost, time, accuracy, revenue)
- Assess data readiness: volume, quality, accessibility, sensitivity
- Audit organizational readiness: skills, governance, change capacity
- Identify the deterministic baseline (rules engine, classical ML) before reaching for an LLM
Tools commonly used: Internal scorecards, data quality profilers, SumatoSoft AI Readiness Assessment framework.
Deliverable: A go/no-go decision document with measurable success criteria, data plan, and risk register.
Common failure mode: Building AI for a problem that a SQL query and a rules engine would solve cheaper and more reliably. Deloitte’s State of AI 2026 survey of 3,235 enterprise leaders found that 42% feel their AI strategy is highly prepared but far fewer are prepared on data (40%), infrastructure (43%), or talent (20%) – a strong signal that “strategy ready” without “data ready” is a leading indicator of failed pilots.
Phase 2 – Token economics and ROI modeling
Goal: Forecast inference cost at production load and compare it to the value being created.
Key activities:
- Estimate prompt and completion token sizes per feature interaction
- Project usage across user cohorts and traffic patterns
- Choose a model tier per feature (e.g., flagship for complex reasoning, smaller model for classification)
- Model worst-case scenarios: a user who hammers the system, a feature that retries
Tools commonly used: Provider pricing pages, internal cost calculators, observability platforms (Langfuse, Helicone, Datadog LLM Observability), SumatoSoft AI development cost modeling.
Deliverable: A cost-per-feature, cost-per-user, and cost-per-outcome model with sensitivity ranges. Token budgets enforced at the application layer.
Common failure mode: Shipping a feature with no inference cap and discovering the bill at month-end. A 100x overrun is not unusual when a viral user finds a way to loop the agent.
Phase 3 – Secure architecture design
Goal: Design an AI architecture that satisfies the customer’s CISO before a single line of inference code is written.
Key activities:
- Choose deployment posture: cloud-hosted model API, dedicated tenant, on-premise model
- Design VPC isolation, RBAC, secret management, and audit logging
- Decide on data retention policy with the model provider (zero retention is the default for regulated workloads)
- Threat-model prompt injection, data exfiltration, and jailbreak surfaces
Tools commonly used: Cloud provider AI services with private networking (Azure OpenAI Service, AWS Bedrock private endpoints, Google Vertex AI), guardrails libraries (NVIDIA NeMo Guardrails, Lakera Guard), policy-as-code frameworks.
Deliverable: Architecture diagram, threat model, security review sign-off, data flow documentation.
Common failure mode: “We’ll add the security controls in v2.” In regulated industries, v2 never ships because the v1 review fails.
Phase 4 – RAG / agent / prompt engineering
Goal: Build the AI system itself – retrieval, orchestration, prompts, tools – to a production-ready quality bar.
Key activities:
- Design the retrieval layer: chunking, embeddings, vector store, hybrid search, re-ranking
- Engineer prompts and system instructions; version-control them
- Define the agent’s tool surface (database reads, API calls, search) and tool policies
- Build the citation and grounding enforcement layer
Tools commonly used: RAG development services and AI agent development, LangChain/LangGraph, LlamaIndex, vector DBs (Pinecone, Weaviate, pgvector), re-ranking models (Cohere Rerank, BGE).
Deliverable: A working RAG or agent system with versioned prompts, retrieval index, and tool definitions, ready for evaluation.
Common failure mode: “Vibes-driven prompting.” Treating prompts as throwaway text instead of versioned engineering artifacts. The fix is to put them in source control and run an eval on every change.
Phase 5 – Red-teaming and algorithmic evaluation
Goal: Systematically attack the system and measure how often, and how badly, it fails.
Key activities:
- Build an evaluation set covering happy path, edge cases, adversarial inputs, and known failure classes
- Run red-team exercises: prompt injection, jailbreaks, sensitive data extraction, unsafe outputs
- Score outputs with automated rubrics (RAGAS for retrieval quality; custom rubrics for domain correctness) and human review for subjective dimensions
- Establish thresholds – e.g., “factuality score ≥ 0.92 on the validation set” – that block release if missed
Tools commonly used: RAGAS, OpenAI Evals, LangSmith, Langfuse, Promptfoo, internal red-team playbooks, Anthropic’s responsible scaling policy as a reference for severity grading.
Deliverable: An evaluation harness that runs in CI, a red-team report, and a documented set of pass/fail thresholds.
Common failure mode: Evaluating only on examples the team wrote. Real adversarial users are more creative than your test set; the eval set must include attempts to break the system.
Phase 6 – Controlled deployment
Goal: Get the system in front of real users without exposing the business to its tail risks.
Key activities:
- Stage rollout: shadow mode → internal users → small cohort → full rollout
- Wire in real-time guardrails: PII detection, output filtering, refusal logic
- Stand up the human-in-the-loop queue and on-call rotation
- Configure budget alerts and circuit breakers (auto-disable a feature if cost or error rate spikes)
Tools commonly used: Feature flag platforms (LaunchDarkly, Unleash), guardrail middleware, observability platforms with LLM tracing, on-call platforms.
Deliverable: A live system with a documented rollback procedure, an active incident response playbook, and a known cost ceiling.
Common failure mode: Big-bang launches. The economics of LLM features punish surprises far more than the economics of traditional features.
Phase 7 – Continuous evaluation and guardrail tuning
Goal: Detect drift, regressions, new failure modes, and cost anomalies after the system is live, and route findings back into earlier phases.
Key activities:
- Run the evaluation harness on a rolling sample of production traffic
- Monitor token cost, latency, refusal rate, and citation rate trends
- Re-run red-team exercises on a fixed cadence (quarterly is a reasonable default)
- Feed regressions back into Phase 4 (prompt/retrieval changes) or Phase 3 (architectural changes)
Tools commonly used: Langfuse, LangSmith, Datadog LLM Observability, Arize Phoenix, custom drift detectors.
Deliverable: A monthly AI health report covering quality, cost, security, and incidents. A backlog of prompt, retrieval, and architectural changes prioritized by impact.
Common failure mode: Treating launch as the finish line. AI systems decay silently; the team that ships and walks away discovers the regression from a customer complaint.
When to use ADLC vs SDLC (decision framework)
Use the following decision tree before starting any new initiative. The goal is to spend ADLC’s overhead only where probabilistic behavior actually exists.

- Deterministic output requirements only? → SDLC. Don’t reach for an LLM because it’s fashionable.
- Probabilistic generation involved? → ADLC. Even a single LLM-powered field justifies the additional gates.
- Using a pretrained model as-is, with no fine-tuning and no agent autonomy? → Lightweight ADLC. Phases 1, 2, 3, 5, 7 are required; Phase 4 is minimal; Phase 6 can be simplified.
- Fine-tuning a model, or orchestrating multi-step agents with tool use? → Full ADLC. All seven phases, with Phase 5 expanded to include agent-trajectory evaluation.
- Hybrid system (AI components plus traditional services)? → Both, with explicit interface contracts. The AI subsystem follows ADLC; the traditional subsystem follows SDLC; the integration layer is governed by the stricter of the two.
ADLC in action: three real-world patterns
The framework only earns its keep when it survives real production. Three patterns from SumatoSoft engagements illustrate which phases mattered most in each.
Wind farm predictive maintenance
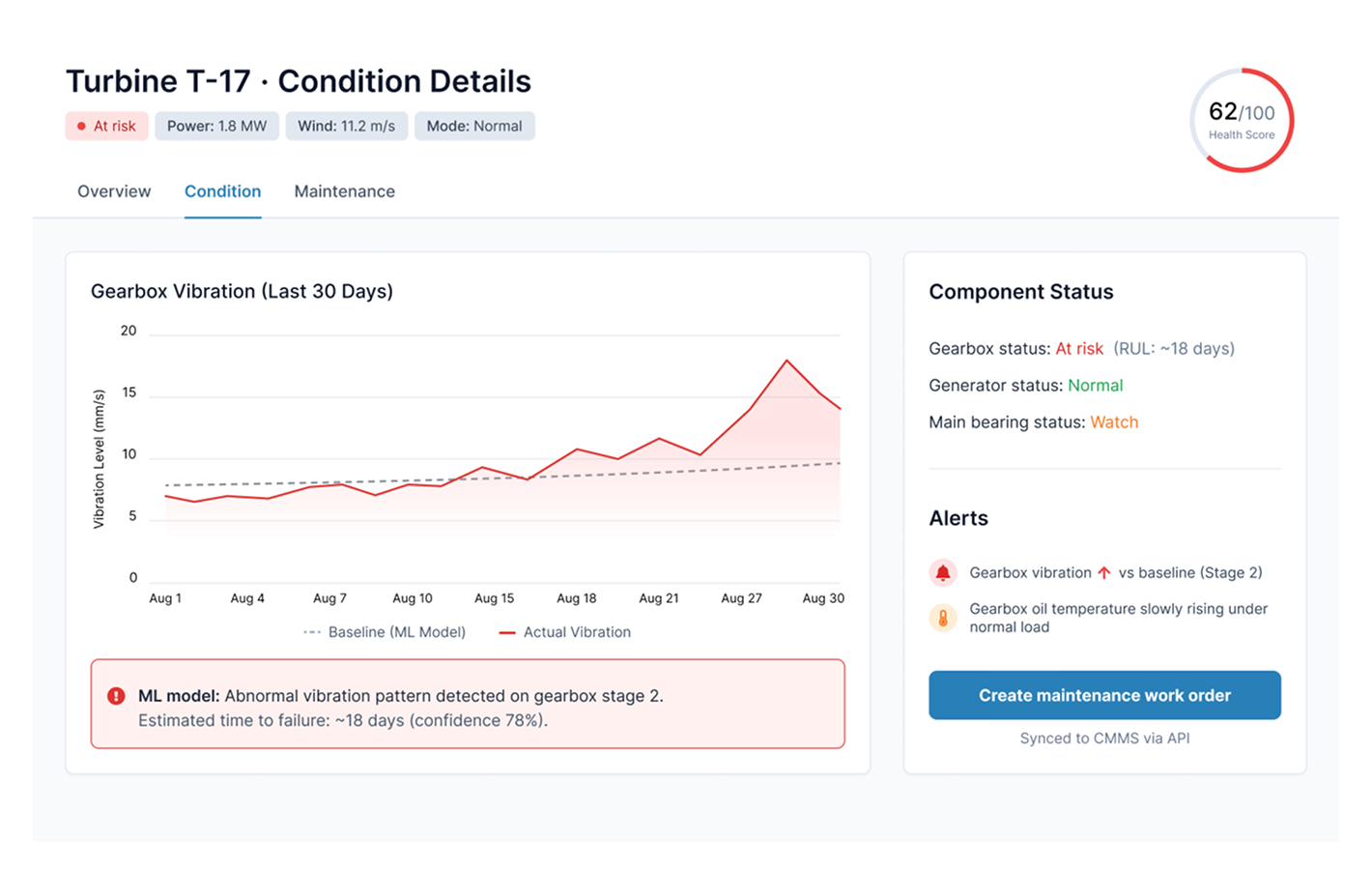
A utility operating 400+ turbines wanted to predict component failures from SCADA telemetry, vibration sensors, and maintenance logs. Phase 1 (readiness) revealed that the maintenance log data was inconsistent across sites – three months of data normalization preceded any modeling. Phase 3 (architecture) drove a VPC-isolated deployment because turbine telemetry is regulated as critical infrastructure data. Phase 7 (continuous evaluation) caught a model drift event triggered by a fleet-wide firmware update three months post-launch – drift that would have been invisible without the evaluation harness running on production traffic.
Clinical trial matching

A medical platform matches patient records to clinical trial inclusion criteria. Phase 5 (red-teaming) was the dominant cost: every false-positive recommendation has clinical and regulatory consequences. The team built a 1,200-case evaluation set, with physician reviewers, and set a precision threshold of 0.95 before release. Multi-modal grounding (Pillar 5) was non-negotiable: trials, patient charts, and inclusion-criteria PDFs all had to enter the context together, with citation enforcement, so every recommendation could be audited.
Freight route optimization with agentic dispatch
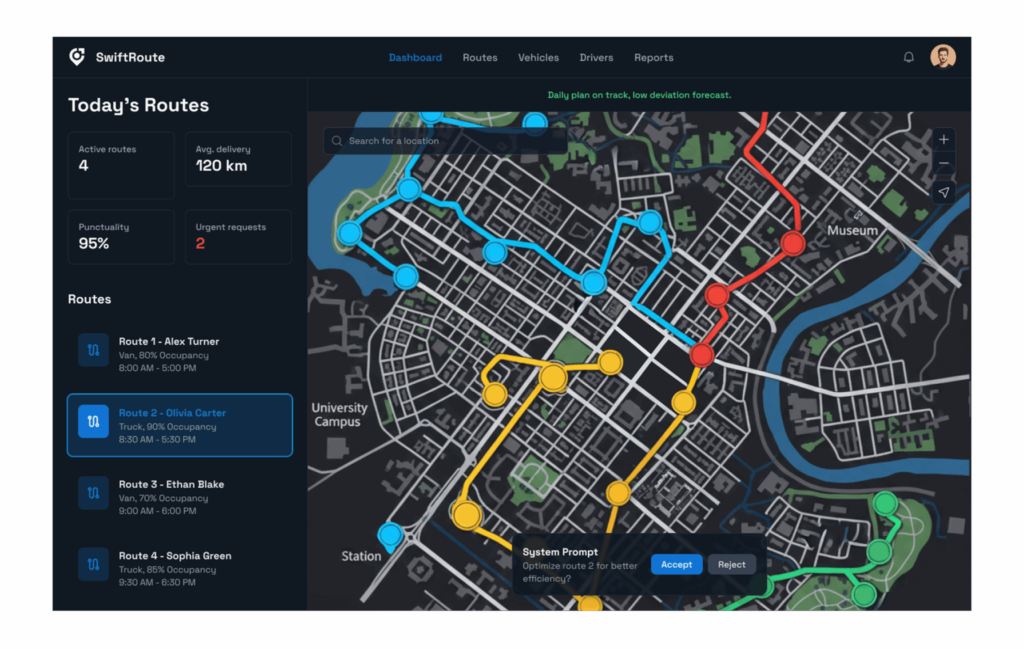
A logistics customer replaced a static routing engine with an agent that negotiates load assignments across carriers. Phase 2 (token economics) caught a design flaw early: the original prompt design would have cost $180,000/month at projected volume. A model-routing layer (cheap model for screening, flagship for negotiations) brought it to $22,000/month. Phase 6 (controlled deployment) ran for nine weeks in shadow mode before a single agent decision affected a real shipment.
These patterns share a common shape: the failure modes lived in the engineering process around the model rather than in the model itself. ADLC names those processes so they can be planned, staffed, and budgeted.
How to transition your team from SDLC to ADLC
Adopting ADLC is an organizational change project. Seven concrete steps follow.
Step #1: Audit your current AI initiatives
List every AI feature in production or planned. Score each on the five pillars: is the architecture grounded, the cost modeled, the security architectural, the human-in-the-loop defined, the grounding multi-modal? Pillars scoring zero are remediation candidates.
Step #2: Introduce AI readiness assessment as gate zero
Every new AI proposal should pass a readiness assessment before any engineering effort starts. The assessment is short (one to two weeks) and produces a binary go/no-go, not a scope document. Its job is to kill projects that should be killed early.
Step #3: Add AI evaluation to your definition of done
A pull request that changes a prompt, a retrieval parameter, or a model version cannot merge without an eval run that meets thresholds. This is the single highest-leverage practice change. It transforms prompt engineering from craft to engineering.
Step #4: Retrain QA engineers on probabilistic testing
QA engineers who built careers on deterministic testing are exactly the right people to run AI evaluation – they think rigorously about edge cases. They need new tools (RAGAS, eval harnesses) and new mental models (distributional regression, slice analysis). A focused four-to-six-week training plan gets most QA teams there.
Step #5: Build token cost dashboards
Cost telemetry should be as visible as latency. Per-feature, per-user, per-tenant. Engineers will not optimize what they cannot see. The dashboard should land in the same review meeting as your weekly latency and uptime metrics.
Step #6: Establish red-team cadence
Schedule quarterly red-team exercises against every production AI system. Use external red-teamers when budget allows; rotate internal red-teamers when it doesn’t. Treat red-team findings as P0 bugs.
Step #7: Document governance decisions (ADR for AI)
Architecture Decision Records (ADRs) are an SDLC tradition. ADLC needs its own variant: an AI Decision Record that captures model choice, prompt versioning policy, evaluation thresholds, and human-in-the-loop boundaries. When the auditor or the next CTO asks “why did we set the threshold at 0.92?” the answer is in the ADR.
Tools and frameworks that support ADLC
A short reference. None of these tools is ADLC; they are infrastructure that makes ADLC practical.
| Category | Representative Tools | ADLC Phase(s) |
|---|---|---|
| Evaluation | RAGAS, OpenAI Evals, Promptfoo, custom rubrics | Phase 5, Phase 7 |
| Observability | LangSmith, Langfuse, Helicone, Arize Phoenix, Datadog LLM Observability | Phase 6, Phase 7 |
| Vector databases | Pinecone, Weaviate, pgvector, Qdrant | Phase 4 |
| Agent orchestration | LangGraph, LlamaIndex, custom orchestration | Phase 4 |
| Guardrails | NVIDIA NeMo Guardrails, Lakera Guard, Llama Guard | Phase 3, Phase 6 |
| Security scanning | Garak, PyRIT, Promptfoo red-team modules | Phase 5 |
| Cost telemetry | Helicone, Langfuse cost tracking, custom dashboards | Phase 2, Phase 7 |
| Model routing | OpenRouter, custom routers, cloud-native (e.g., Azure OpenAI deployments) | Phase 2, Phase 4 |
Frequently asked questions
What is the Agentic Development Lifecycle (ADLC)?
The Agentic Development Lifecycle (ADLC) is a software engineering framework for developing probabilistic AI systems with governance, cost predictability, and security controls built in. It defines five engineering pillars and seven phases that take an AI initiative from a business hypothesis through to continuously evaluated production. ADLC is meant to be adopted alongside, not instead of, an existing SDLC practice.
How is ADLC different from SDLC?
Traditional SDLC was designed for deterministic systems. ADLC extends it for probabilistic ones. SDLC’s testing model assumes reproducible outputs; ADLC replaces it with evaluation harnesses that score against intent. SDLC’s cost model assumes fixed infrastructure; ADLC adds token economics. SDLC’s security model assumes input is data; ADLC adds prompt injection as a first-class threat surface. The difference is not philosophical – it is a list of specific engineering disciplines that probabilistic systems require and deterministic systems do not.
What are the phases of ADLC?
ADLC has seven phases: (1) AI Readiness and Value Assessment, (2) Token Economics and ROI Modeling, (3) Secure Architecture Design, (4) RAG/Agent/Prompt Engineering, (5) Red-Teaming and Algorithmic Evaluation, (6) Controlled Deployment, and (7) Continuous Evaluation and Guardrail Tuning. Phase 7 feeds back into phases 2 and 3, making the lifecycle a continuous loop rather than a linear waterfall.
Who should use ADLC?
Engineering organizations building or operating systems that include probabilistic AI components – chiefly LLM-powered features, agentic systems, and fine-tuned models. Primary adopters are CTOs, VPs of Engineering, AI Architects, and Heads of AI Governance. Regulated industries (finance, healthcare, legal) benefit disproportionately because ADLC’s security and evaluation practices map cleanly onto compliance requirements.
Does ADLC replace Agile or DevOps?
No. ADLC is orthogonal to Agile and DevOps. Sprints, CI/CD, infrastructure-as-code, and observability practices remain. ADLC adds AI-specific gates (evaluation thresholds, token budgets, red-team cadence) that fit inside an existing Agile workflow. Sprints continue at the same cadence, while the work that happens inside each iteration expands to include AI-specific gates.
What tools are used in ADLC?
ADLC is tool-agnostic. Common building blocks include RAGAS or OpenAI Evals for evaluation, LangSmith or Langfuse for observability, Pinecone or pgvector for retrieval, NVIDIA NeMo Guardrails or Lakera Guard for runtime safety, and the major cloud AI services (Azure OpenAI, AWS Bedrock, Google Vertex AI) for secure model deployment. The framework specifies what must be done in each phase; teams choose the tools that fit their stack.
How long does it take to adopt ADLC in an organization?
A first production system built with ADLC typically takes 12 to 20 weeks from kickoff, depending on regulatory scope. Organization-wide adoption – readiness assessments as a gate, evaluation in CI, cost dashboards, red-team cadence – is a six-to-twelve-month change program for a mid-sized engineering org. The decisive accelerator is leadership commitment to “no merge without an eval”; the decisive blocker is treating ADLC as a documentation exercise instead of a working practice.
About SumatoSoft
SumatoSoft is an AI-powered custom software development company that has been delivering enterprise software since 2012. We are a dual-engine engineering firm, working in both the traditional SDLC process and our proprietary Agentic Development Lifecycle (ADLC) – the framework described in this article. Our Clients are established companies that need custom software for further business growth, and our deep expertise in AI, IoT, and machine learning lets us ship governed, secure, and cost-predictable AI systems for production use.
Headquartered in Boston, Massachusetts (One Boston Place, Suite 2602), we serve Clients across the United States, Europe, the United Kingdom, and worldwide. We work across Healthcare, FinTech, Logistics, e-Learning, Manufacturing, and Marketing, with a particular focus on data-rich, regulated, and operational-critical environments where AI failure modes are not acceptable.
| Metric | Number | What it means |
|---|---|---|
| Years on the market | 14+ | Founded in 2012; built deep institutional knowledge across SDLC and now ADLC delivery. |
| Successful projects delivered | 350+ | From POCs to production-grade AI, IoT, and enterprise platforms. |
| Countries served | 25+ | Including the USA, EU, and the UK. |
| Client satisfaction rate | 98% | Measured across post-engagement reviews. |
| Senior engineering specialists | 70% | Of our delivery team are senior-level – critical for ADLC red-teaming and evaluation work. |
| Industries we serve | 6 core | Healthcare, FinTech, Logistics, e-Learning, Manufacturing, Marketing. |
| Areas of expertise | AI, IoT, ML, Enterprise | Custom software, AI/ML, IoT, machine learning, enterprise software development. |
Our cultural code:
- Be transparent
- Focus on business-value delivery
- Teamwork and cooperation.
From the early stages, their team demonstrated a strong understanding of our business domain and the constraints of working with existing SCADA systems. They took a proactive approach, carefully analyzing our requirements and proposing a solution that enhanced our infrastructure without disrupting it. Communication was clear and structured, and the project was managed professionally, with all milestones delivered on time.
The resulting platform gave us a unified view of turbine health and enabled early detection of gearbox and generator issues. This helped reduce unplanned downtime and emergency maintenance activities. Overall, SumatoSoft proved to be a reliable and knowledgeable technology partner focused on delivering real business value.

Conclusion – from experimental AI to engineered AI
For three years, enterprise AI has been an experiment dressed up as a product. Pilots launched, demos impressed, and most never reached the second budget cycle. Gartner’s projection that more than 40% of agentic AI projects will be canceled by the end of 2027 is not a surprise – it’s a description of what happens when probabilistic systems are managed with deterministic processes.
ADLC is one attempt to codify how to do better. Adopting ADLC won’t guarantee that AI projects succeed. What it does deliver is fewer failures for the wrong reasons – runaway costs, ungoverned drift, security perimeters that didn’t account for prompt injection, evaluation that amounted to “looks good to me.” The work itself is unglamorous: token budgets, eval harnesses, red-team playbooks, decision records. None of it is exotic. All of it is necessary.
The organizations that get this right in 2026 and 2027 will treat AI as engineering rather than as a research project – with the same seriousness, the same governance, and the same boring, indispensable rigor that produced four decades of reliable software.
Let’s start
If you have any questions, email us info@sumatosoft.com










