Case Study: AI-powered knowledge base platform for a global nonprofit organization
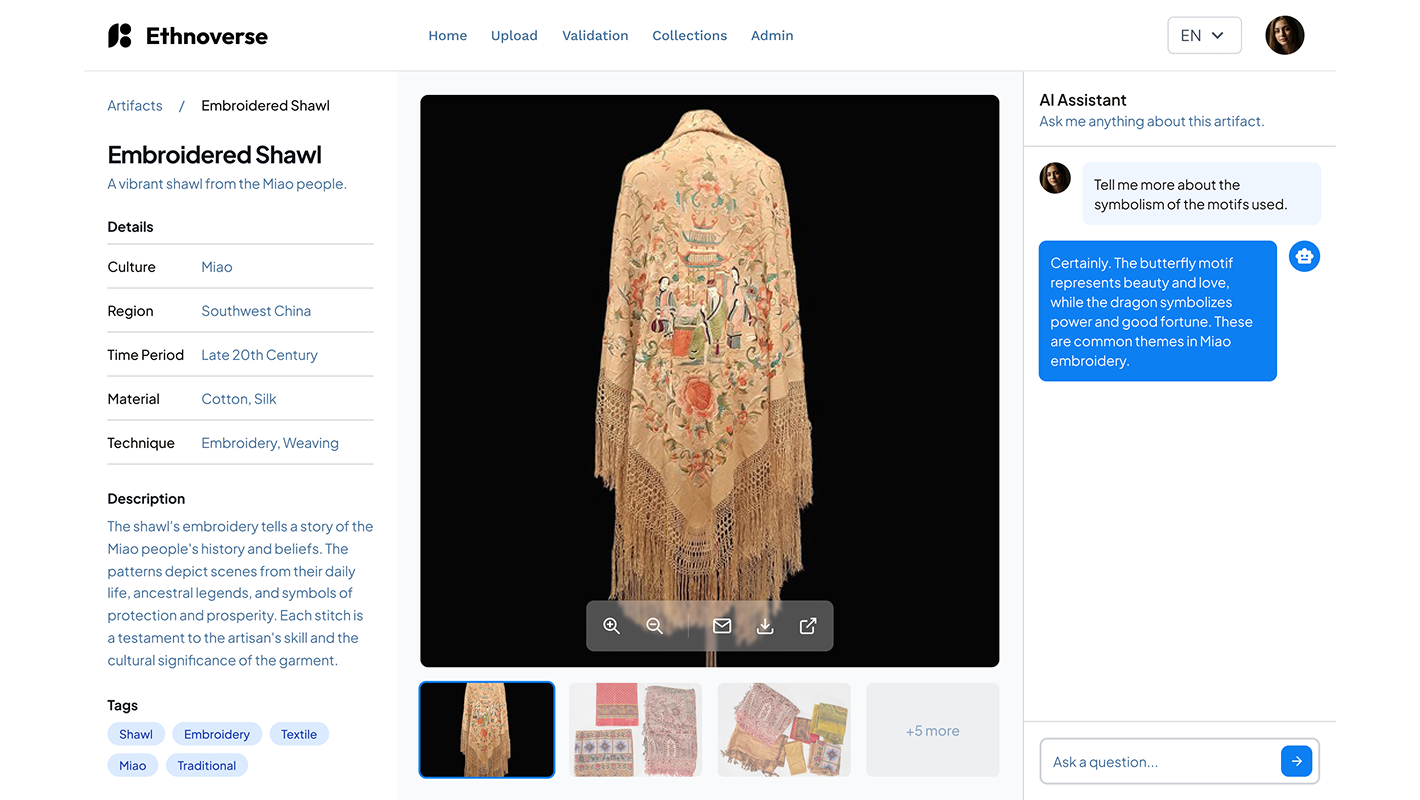
A global nonprofit headquartered in the Middle East works on cultural preservation and supports legal cases on ethnic minorities’ rights. Source material sat in fragmented archives across community libraries, field collections, and government files, mostly in their original languages and outside any central catalog. SumatoSoft built a multilingual web platform that ingests documents, photographs, video, and manuscript scans, runs OCR, auto-translates metadata into 15 languages, and lets users query a 12,000-artifact base through filters or an AI assistant. Research time per topic dropped from around 12 hours to roughly 25 minutes, and the platform now serves 240+ researchers, policymakers, advocates, and contributors across 18 countries.
Project details:
About the Client:
A global nonprofit headquartered in the Middle East, working in cultural preservation and supporting policy and legal work on ethnic minorities’ rights.
Location: Middle East
Industry: Non-profit
Team size: 8 specialists (business analysts, project managers, software architects, developers, and UX/UI designers)
Project duration: 6 months
Business challenge
The Client needed a single searchable resource for material on ethnic minorities, sourced from community libraries, field research, government records, and photographic collections across 18 countries. Material sat in fragmented archives in many languages, and most artifacts needed translation before researchers, policymakers, or advocates could use them. Baseline averaged around 12 hours of research per topic, and outside translation costs the Client roughly $80,000 a year.
Additional requirements:
- Digitize physical and digital artifacts into a searchable format
- Handle documents, photographs, video, and manuscript scans through one ingest pipeline
- Support automatic translation across all 15 working languages
- Run with role-based access and a validator workflow suitable for legal work
Our solution
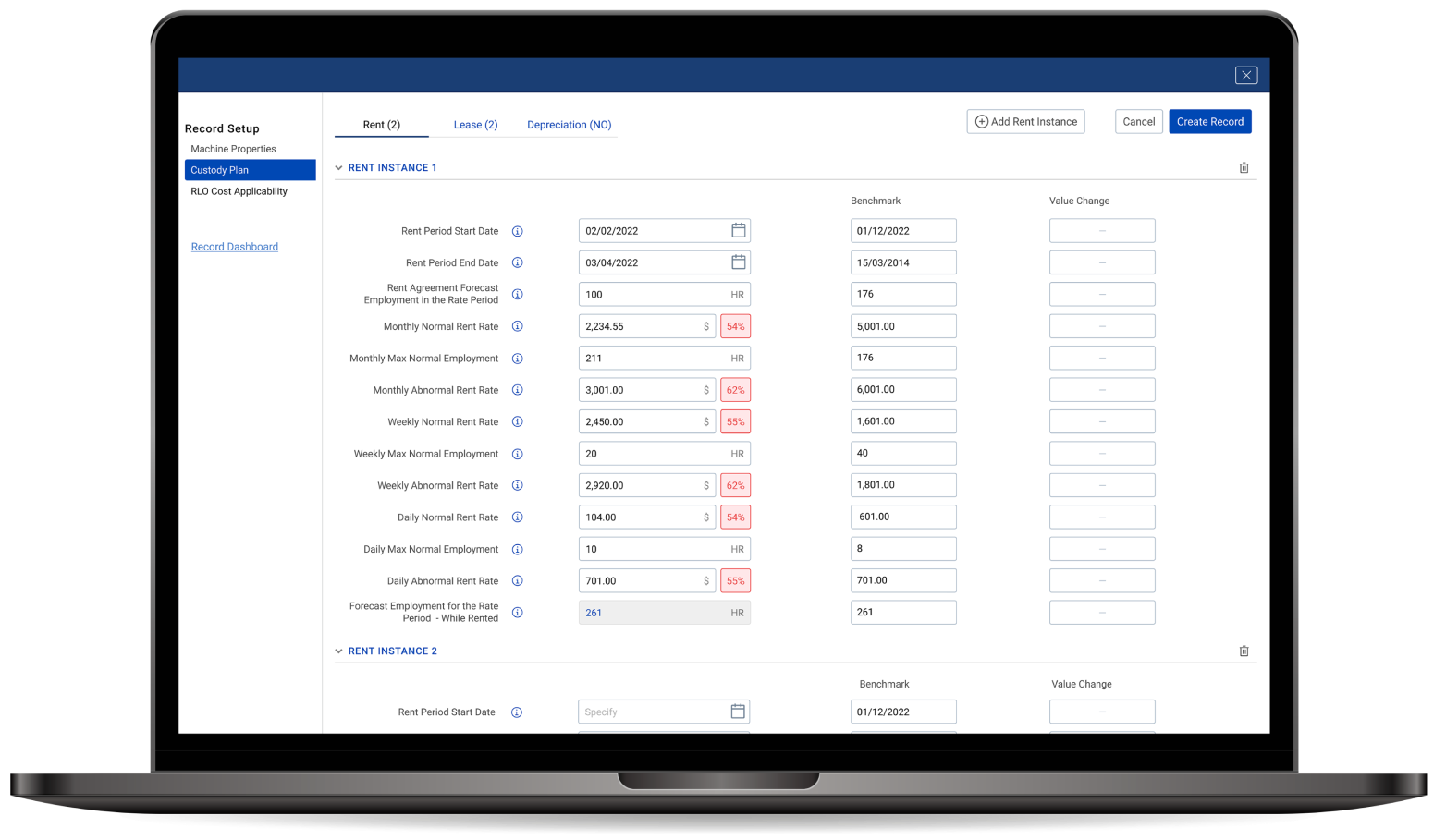
We built a responsive web platform that consolidates the Client’s source material into a single searchable database. The ingest pipeline accepts documents, photographs, video, and manuscript scans; OCR extracts text from scans and handwritten material; and OpenAI’s NLP models translate metadata into 15 languages and index content for cross-language search. Files are stored on AWS, encrypted, and protected by role-based access controls. We shipped the platform in two releases: the core ingest, search, and visualization layer first, then the AI assistant. In validated test cycles, OCR achieved 96% accuracy on printed text and 84% on manuscripts; the assistant returned 89% of researcher queries within acceptable relevance thresholds; and translations cleared expert review at 87%.
AI-powered chatbot integration
The integration of a GPT-like chatbot was one of the most complex aspects of the project. It required advanced natural language processing capabilities to support multilingual queries, contextual analysis, and the ability to generate insights based on user interactions.

Additional information about the case
Researchers open a catalog view of artifacts and pivot through filters by artifact type, region, time period, culture, and language. Visualization tools render interactive timelines, relationship maps, comparative metrics, and side-by-side artifact views for cross-artifact analysis. The validator workflow keeps origin and authenticity checks separate from the public catalog, with role-based access across six user roles.
Additional features:
- Support for documents, photographs, video, and manuscript scans, with OCR text extraction
- Automatic translation of metadata into 15 languages, plus multilingual interfaces
- Timelines, relationship maps, comparative metrics, and artifact comparison views
- Admin module covering artifacts, user roles, and validator workflows

Business value
Before:
-
- Researchers spent around 12 hours per topic gathering material across fragmented archives, with ~45 minutes per artifact lookup.
- Most artifacts existed in their original language, and translation outside that language ran the Client roughly $80,000 a year.
- No central catalog existed, so the same artifact often surfaced twice across projects or went missing between them.
- Policy and legal work moved slowly: evidence had to be retranslated, reverified, and reattributed for every initiative.
- Visual material sat in scans that no one could search, and OCR was handled ad hoc by contractors.
After:
- Research time per topic dropped from around 12 hours to roughly 25 minutes, with artifact-level lookups down to ~30 seconds.
- Automatic translation across 15 languages cuts outside translation spend by around 70%, or roughly $56,000 a year.
- The catalog holds 12,000+ artifacts, indexed, deduplicated, and authenticated through the validator workflow.
- Policymakers and legal advocates draw on shared, vetted material in hours instead of weeks; 14 active advocacy and legal initiatives now build evidence directly on the platform.
- OCR brings visual material into search, and 240+ researchers, policymakers, advocates, and contributors across 18 countries use the platform each month.
Have an app idea?
Let’s start with a free quote!
See our other case studies
Counter-service POS for an 8-location Dutch beer & snack chain


A media buying system for a leading US-based advertising agency

Cost management platform development